2020-08-05
03:55:49
7965

MYSQL索引优化
一. 数据准备
生成百万测试数据用于测试索引优化查询
步骤:
-
创建内存表
test_user_memory和普通表test_user -
创建函数用于生成数据
-
创建存储过程在向表内插入数据
-
通过函数循环执行 INSERT INTO 普通表 SELECT * FROM 内存表;加快数据生成。
- 因为通过存储过程一条一条将数据插入表内速度很慢,而一次性把内存表的数据插入到普通表,这个过程是很快的
1)创建普通表 test_user
CREATE TABLE `test_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` varchar(36) NOT NULL COMMENT '用户id',
`user_name` varchar(30) NOT NULL COMMENT '用户名称',
`phone` varchar(20) NOT NULL COMMENT '手机号码',
`lan_id` int(9) NOT NULL COMMENT '本地网',
`region_id` int(9) NOT NULL COMMENT '区域',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8mb4 COMMENT='普通表';
2)创建内存表 test_user_memory
CREATE TABLE `test_user_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` varchar(36) NOT NULL COMMENT '用户id',
`user_name` varchar(30) NOT NULL COMMENT '用户名称',
`phone` varchar(20) NOT NULL COMMENT '手机号码',
`lan_id` int(9) NOT NULL COMMENT '本地网',
`region_id` int(9) NOT NULL COMMENT '区域',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=MEMORY AUTO_INCREMENT=51250 DEFAULT CHARSET=utf8mb4 COMMENT='内存表';
3 ) 创建生成数据的函数
- 创建生成n个随机数字的函数,生成手机号码字段的数据时需要用到
DELIMITER $$
CREATE FUNCTION randNum(n int) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str varchar(20) DEFAULT '0123456789';
DECLARE return_str varchar(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*10 ),1));
SET i = i +1;
END WHILE;
RETURN return_str;
END $$
DELIMITER;
- 生成随机手机号码函数
- 定义常用的手机头 :130 131 132 133 134 135 136 137 138 139 186 187 189 151 157
- SET head = substring(bodys,starts,3); 在字符串bodys中从starts位置截取三位
DELIMITER $$
CREATE FUNCTION generatePhone () RETURNS VARCHAR ( 20 ) BEGIN
DECLARE
head CHAR ( 3 );
DECLARE
phone VARCHAR ( 20 );
DECLARE
bodys VARCHAR ( 100 ) DEFAULT "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
DECLARE
STARTS INT;
SET STARTS = 1+floor ( rand()* 15 )* 4;
SET head = trim(
substring( bodys, STARTS, 3 ));
SET phone = trim(
concat(
head,
randNum ( 8 )));
RETURN phone;
END $$DELIMITER;
- 创建随机字符串和随机时间的函数
DELIMITER $$
CREATE FUNCTION `randStr` ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$DELIMITER;
4 ) 创建插入数据的存储过程
- 创建插入内存表数据存储过程 ,入参n是多少就插入多少条数据
DELIMITER $$
CREATE PROCEDURE `add_test_user_memory` ( IN n INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
INSERT INTO test_user_memory ( user_id, user_name, phone, lan_id, region_id, create_time )
VALUES
(
uuid(),
randStr ( 20 ),
generatePhone (),
FLOOR( RAND() * 1000 ),
FLOOR( RAND() * 100 ),
NOW());
SET i = i + 1;
END WHILE;
END $$DELIMITER;
- 创建内存表数据插入普通表存储过程
- 此处利用对内存表的循环插入和删除来实现批量生成数据,这样可以不需要更改mysql默认的max_heap_table_size值也照样可以生成百万或者千万的数据。
- max_heap_table_size默认值是16M。
- max_heap_table_size的作用是配置用户创建内存临时表的大小,配置的值越大,能存进内存表的数据就越多。
#参数描述 n表示循环调用几次;count表示每次插入内存表和普通表的数据量
DELIMITER $$
CREATE PROCEDURE `add_test_user_memory_to_outside` ( IN n INT, IN count INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
CALL add_test_user_memory ( count );
INSERT INTO test_user SELECT
*
FROM
test_user_memory;
DELETE
FROM
test_user_memory;
SET i = i + 1;
END WHILE;
END $$DELIMITER;
- 调用存储过程生成数据
将以上函数和存储过程都创建完毕后,通过执行存储过程生成数据。
#先调用存储过程往内存表插入一万条数据,然后再把内存表的一万条数据插入普通表
CALL add_test_user_memory(10000);
#一次性把内存表的数据插入到普通表,这个过程是很快的
INSERT INTO test_user SELECT * FROM test_user_memory;
#清空内存表数据
delete from test_user_memory;
测试往内存表内生成一万条数据需要多久:

而把内存表的一万条数据一次性插入普通表,只需要很短的时间:

查看数据是否插入test_user表: (一万条数据成功插入)

因为现在还没有更改数据库默认的内存表可容纳的内存大小,所以单次插入内存表一万条数据是没问题的,但是单次插入内存表十万条数据就不行了,会报内存表已满的异常:

所以想插入百万条测试数据,可以通过执行add_test_user_memory_to_outside存储过程,循环调用 INSERT INTO test_user SELECT * FROM test_user_memory;语句插入数据;
#第一个参数表示循环次数,第二个参数表示每次生成的数据;100*10000=一百万
CALL add_test_user_memory_to_outside(100,10000);
但这样耗时太长,且每次不能插入太多数据量(插入数据过多mysql会报内存已满的异常)
可以通过修改mysql的内存默认值,通过调用一次存储过程插入普通表十万或百万的数据
#通过执行mysql命令修改
SET GLOBAL tmp_table_size=2147483648;
SET GLOBAL max_heap_table_size=2147483648;

修改完成后,需要重启mysql进程才可生效;再次单次插入10万以上数据量可以正常插入,不会再报内存已满异常

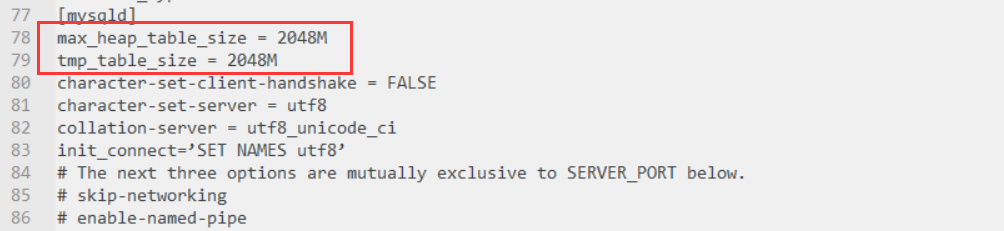
如果 SET GLOBAL修改内存后,插入10万条数据还是报内存已满的异常,可以修改my.ini的配置文件:
在[mysqld]下加上这两行,mysql的max_heap_table_size默认值是16M ( 修改完成后需重启mysql进程生效 )
[mysqld]
max_heap_table_size = 2048M
tmp_table_size = 2048M
生成百万条测试数据:(这个过程大概需要8到10分钟)
#第一个参数表示循环次数,第二个参数表示每次生成的数据;10*100000=一百万
CALL add_test_user_memory_to_outside(10,1000000);

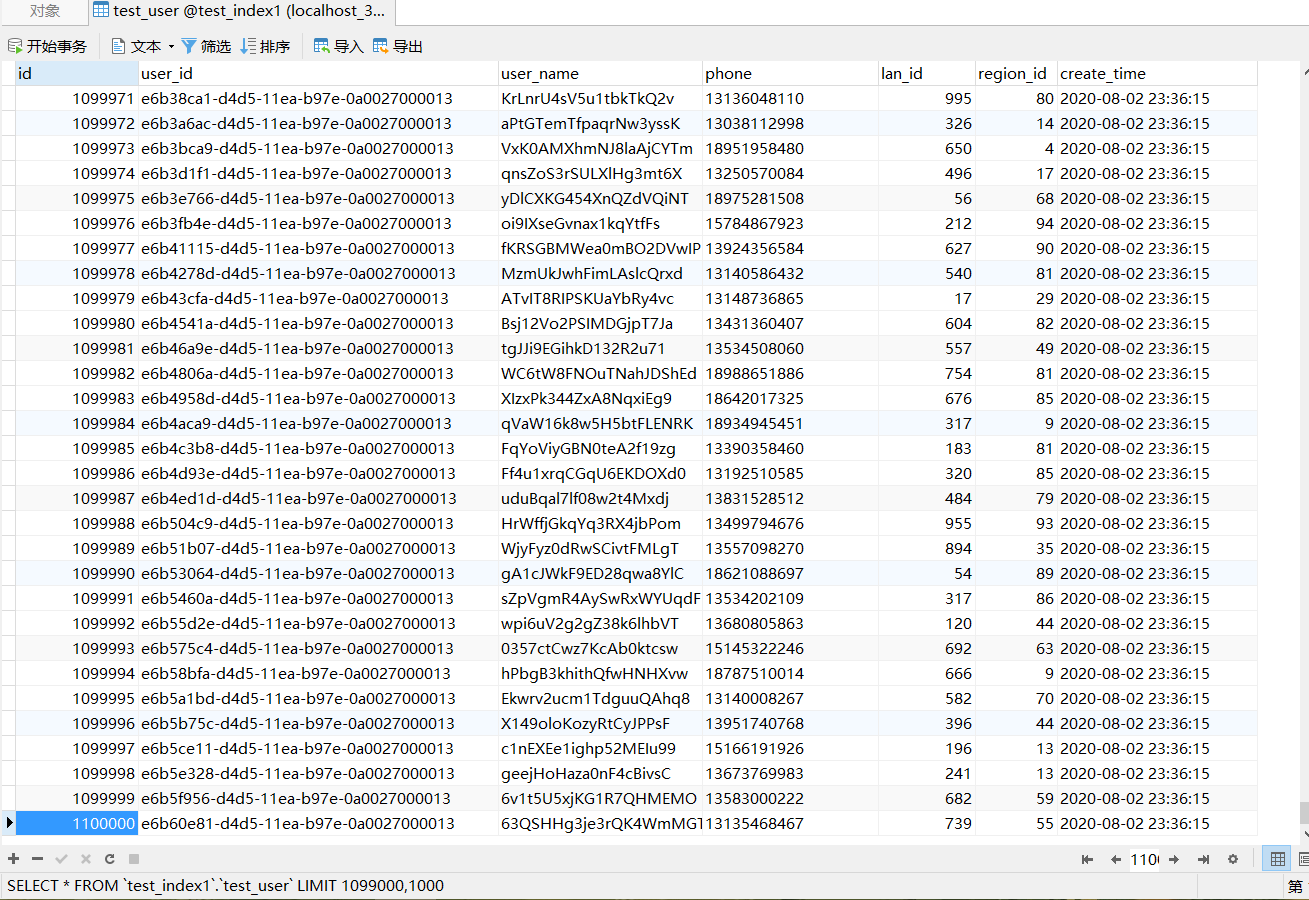
至此,测试数据准备完毕。
二. 索引查询优化
通过查看test_user的表结构,可以看到当前索引为空
没有索引的情况下,测试在百万的数据量里查询一条数据需要耗时:
SQL_NO_CACHE关键字表示无缓存查询,确保查询时间的真实准确性
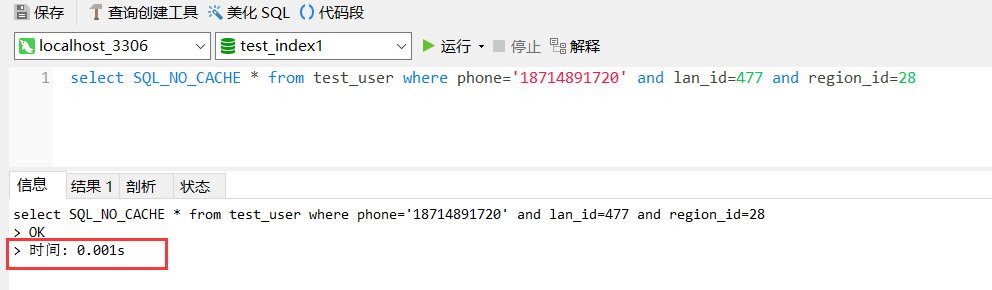
select SQL_NO_CACHE * from test_user where phone='18714891720' and lan_id=477 and region_id=28


无索引情况下查询一条数据需要0.43秒
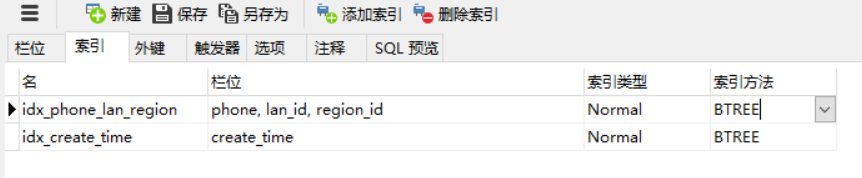
为test_user表添加一个复合索引(即一个索引包含多个字段)
ALTER TABLE test_user ADD INDEX idx_phone_lan_region(phone, lan_id, region_id);
执行完成语句后查看索引创建:

索引创建完成后,再次运行查询语句:(执行时间缩短为0.001秒)
2.1 EXPLAIN关键字
EXPLAIN关键字,可以用来分析SQL语句的执行计划;查看SQL语句查询是否命中索引。
也可以使用DESCRIBE或DESC,语法一样。
使用:在查询语句前加上EXPLAIN关键字
EXPLAIN select SQL_NO_CACHE * from test_user where phone='18714891720' and lan_id=477 and region_id=28

以上表示该查询使用到了idx_phone_lan_region索引,ref表明使用了三个常量命中索引去查找;
explain结果值及其含义:
| 参数值 | 含义 |
|---|---|
| id | 表示SELECT语句的编号; |
| select_type | 表示SELECT查询语句的类型。 该参数有几个常用的取值:1)SIMPLE :表示简单查询,其中不包括连接查询和子查询; 2)PRIMARY:表示主查询,或者是最外层的查询语句;3)UNION:表示连接查询的第二个或后面的查询语句; |
| table | 表示查询的表; |
| type | 表示表的连接类型。该参数有几个常用的取值:1)const :表示表中有多条记录,但只从表中查询一条记录。2)eq_ref :表示多表连接时,后面的表使用了UNIQUE或者PRIMARY KEY。3)ref :表示多表查询时,后面的表使用了普通索引。4)unique_ subquery:表示子查询中使用了UNIQUE或者PRIMARY KEY。5)index_ subquery:表示子查询中使用了普通索引。 6)range:表示查询语句中给出了查询范围。7)index:表示对表中的索引进行了完整的扫描。8)system:系统表,少量数据,往往不需要进行磁盘IO。9)all:表示此次查询进行了全表扫描(该条SQL需要优化)。上面各类扫描方式由快到慢顺序为:system > const > eq_ref > ref > range > index > ALL |
| possible_keys | 表示查询中可能使用的索引;如果备选的数量大于3那说明已经太多了,因为太多会导致选择索引而损耗性能, 所以建表时字段最好精简,同时也要建立联合索引,避免无效的单列索引; |
| key | 表示查询使用到的索引; |
| key_len | 表示索引字段的一长度; |
| ref | 表示使用哪个列或常数与索引一起来查询记录; |
| rows | 表示查询的行数;试图分析所有存在于累计结果集中的行数,虽然只是一个估值,却也足以反映 出SQL执行所需要扫描的行数,因此这个值越小越好; |
| Extra | 表示查询过程的附件信息。(会备注是否使用了索引信息等) |
2.2 索引优化
- 优化一:全部用到索引
建立的复合索引包含了几个字段,查询的时候最好能全部用到,而且严格按照索引顺序,这样查询效率是最高的。(最理想情况)
创建的索引idx_phone_lan_region内字段顺序是phone, lan_id, region_id,而查询的时候也按照这个顺序来拼接and条件,则这种情况下查询时间最短;
- 优化二:最左前缀法则
如果建立的是复合索引,索引的顺序要按照建立时的顺序,即从左到右,如:a->b->c(和 B+树的数据结构有关)
如果查询时的查询条件字段未按照创建索引的顺序,则可能会导致后面字段的索引失效
idx_phone_lan_region复合索引的字段顺序为phone, lan_id, region_id。
无效索引举例:
1)查询时使用 a and c作为查询条件:a 有效,c 无效,因为中间缺少b
查询的连接条件缺少了中间的lan_id,ref表明只使用了一个常量查询命中了索引

2)查询时使用 b and c作为查询条件:b、c 都无效,因为缺少a
查询的连接条件缺少了开头的phone,ref与key为空表面该条查询没有使用到索引

3)查询时只使用c字段作为查询条件:a、b、c 索引都无效
查询的连接条件只有索引字段顺序最后的region_id,ref与key为空表面该条查询没有使用到索引
就好比过桥,如果桥头都没有则无法走到桥中与桥尾,没有桥中也无法走到桥尾。
- 优化三:不要对索引做以下处理,以下用法会导致索引失效
- 计算,如:+、-、*、/、!=、<>、is null、is not null、or
- 函数,如:sum()、round()等等
- 手动/自动类型转换,如:id = "1",本来是数字,给写成字符串了
使用 is not null导致索引失效

- 优化四:索引不要放在范围查询右边
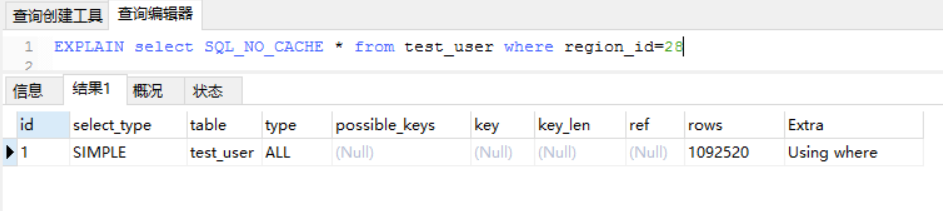
比如复合索引:a->b->c,当 where a=' ' and b>10 and c=' ',这时候索引只能用到 a 和 b,c 用不到索引,因为在范围之后索引都失效(和 B+树结构有关)
中间字段使用了>导致 region_id索引失效,type=range表示使用了范围查找索引

将连接条件 region_id=28 去掉查询,key_len索引长度与没去掉一致,都是86,说明当中间为范围查询时,没有使用到右边的region_id索引

- 优化五:减少 select * 的使用
使用select * 会导致覆盖索引失效且会查找很多不必要的字段。
覆盖索引:即 select 查询的字段与 where 连接条件字段一致。
例:查询语句 select a , b from table where a=1 and b=2;
虽然查询条件缺少phone导致创建的 idx_phone_lan_region索引失效,但是命中了覆盖索引。

将查询条件 lan_id,region_id改为 * ,则没有使用索引

- 优化六:不使用like 左模糊查询
使用like导致索引失效情况: 1) like "%张三%" 2)like "%张三"
1)因为phone使用了左模糊查询导致索引失效

2)如果必须要使用到左模糊查询,可以使用覆盖索引,即 like 字段是 select 查询内的字段

3)使用右模糊查询 like "张三%"

- 优化七:order by 优化
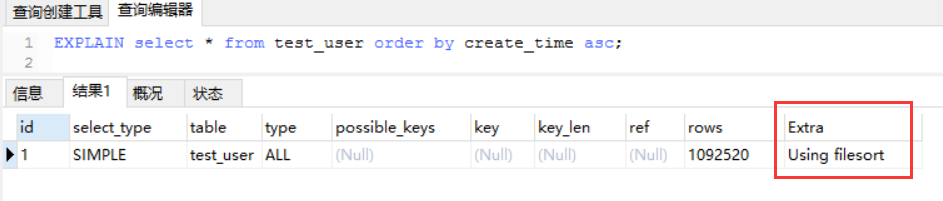
当查询语句中使用 order by 进行排序时,如果没有使用索引进行排序,会出现 filesort 文件内排序,这种情况在数据量大或者并发高的时候,会有性能问题,需要优化。
首先给 create_time 字段建立一个单值索引 idx_create_time,用于测试
ALTER TABLE test_user ADD INDEX idx_create_time(create_time);
filesort 出现的情况举例:
1)order by 字段不是索引字段

2)order by 字段是索引字段,但是 select 中没有使用覆盖索引,如:select * from test_user order by create_time asc;
3)order by 中同时存在 ASC 升序排序和 DESC 降序排序,如:select lan_id, region_id from test_user order by lan_id desc, region_id asc;

4)order by 多个字段排序时,不是按照索引顺序进行 order by,即不是按照最左前缀法则 select a, b from test_user order by b asc, a asc;
正确使用:命中覆盖索引

但在实际使用时,覆盖索引排序一般无法满足业务需求,所以可以通过以下方式优化
索引层面解决方法:
- 使用主键索引排序
- 按照最左前缀法则,并且使用覆盖索引排序,多个字段排序时,保持排序方向一致
- 在 SQL 语句中强制指定使用某索引,force index(索引名字)
- 不在数据库中排序,在代码层面排序
优化八:group by
其原理也是先排序后分组,其优化方式可参考order by。where高于having,能写在where限定的条件就不要去having限定了。
三. 索引概念
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构,索引的目的是提高查询效率,可以类比英语新华字典,如果我们要查询MySQL这个单词,首先我们需要在目录(索引)定位到M,然后在定位到y,以此类推找到SQL。
如果没有索引呢,那就需要从A到Z,去遍历的查找一遍,直到找到我们需要的,一个一个找和直接根据目录定位到数据,查询时间差的天壤之别,这就是索引的妙用。
索引底层数据结构:
当数据量大的时候,索引的数据量也很大,所以索引不可能全部放到内存中,因此索引一般以文件的形式存储到硬盘上。
数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些结构以某种方式指向数据,这样就可以基于这些数据结构实现高级查找算法。
索引算法种类
- B-tree索引(重点掌握,之后文章详细讲解)
- Hash索引
- full-text索引
- R-tree索引
索引的优势:
-
类似大学图书馆书目索引,提高数据检索效率,降低数据库IO成本
-
通过索引列对数据进行排序,降低数据排序成本,降低了CPU消耗
索引的劣势:
-
实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
-
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如果对表INSERT,UPDATE和DELETE。因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
-
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
索引分类:
-
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引:索引列的值必须唯一,但允许有空值
-
复合索引:即一个索引包含多个列
索引语法:
#创建方式一
create [unique] index indexName on tableName (columnName (length))。
#创建方式二
alter tableName add [unique] index [indexName] on (columnName (length))
#删除
DROP INDEX [indexName] ON mytable;
#查看
SHOW INDEX FROM table_name\G
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定length。
哪些情况需要建索引:
-
主键自动建立唯一索引
-
频繁作为查询的条件的字段应该创建索引
-
查询中与其他表关联的字段,外键关系建立索引
-
频繁更新的字段不适合创建索引:因为每次更新不单单是更新了记录还会更索引,加重IO负担
-
Where条件里用不到的字段不创建索引
-
单间/组合索引的选择问题(在高并发下倾向创建组合索引)
-
查询中排序的字段,若通过索引去访问将大大提高排序的速度
-
查询中统计或者分组字段
哪些不适合建索引:
-
表记录太少
-
经常增删改的表
-
数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
四. 慢查询SQL日志
- 慢查询日志是
MySQL提供的一种日志记录,它用来记录查询响应时间超过阀值的SQL语句 - 这个时间阀值通过参数
long_query_time设置,如果SQL语句查询时间大于这个值,则会被记录到慢查询日志中,这个值默认是10秒 MySQL默认不开启慢查询日志,在需要调优的时候可以手动开启,但是多少会对数据库性能有点影响
开启慢查询日志:
#查看是否开启了慢查询日志
SHOW VARIABLES LIKE '%slow_query_log%'
#用命令方式开启慢查询日志,但是重启MySQL后此设置会失效
set global slow_query_log = 1
#永久生效开启方式可以在my.cnf里进行配置,在[mysqld]下新增以下两个参数,重启MySQL即可生效
slow_query_log=1
slow_query_log_file=日志文件存储路径

慢查询时间阀值:
#查看慢查询时间阀值
SHOW VARIABLES LIKE 'long_query_time%';
#修改慢查询时间阀值 单位秒
#修改后的时间阀值生效,需要重新连接或者新开一个回话才能看到修改值。
set global long_query_time=3;
在MySQL配置文件中修改时间阀值:
[mysqld]下配置
slow_query_log=1
slow_query_log_file=日志文件存储路径
long_query_time=3
log_output=FILE
MySQL

评论